Helm¶
用於在 Kubernetes 上部署 vLLM 的 Helm Chart
Helm 是 Kubernetes 的包管理器。它有助於自動化 vLLM 應用在 Kubernetes 上的部署。使用 Helm,您可以透過覆蓋變數值,將相同的框架架構以不同的配置部署到多個名稱空間。
本指南將引導您完成使用 Helm 部署 vLLM 的過程,包括必要的先決條件、Helm 安裝步驟以及架構和值檔案的文件。
先決條件¶
在開始之前,請確保您具備以下條件
- 正在執行的 Kubernetes 叢集
- NVIDIA Kubernetes 裝置外掛 (
k8s-device-plugin):可在此處找到 https://github.com/NVIDIA/k8s-device-plugin - 叢集中可用的 GPU 資源
- 包含待部署模型的 S3 儲存桶
安裝 Chart¶
使用釋出名稱 test-vllm 安裝 Chart
helm upgrade --install --create-namespace \
--namespace=ns-vllm test-vllm . \
-f values.yaml \
--set secrets.s3endpoint=$ACCESS_POINT \
--set secrets.s3bucketname=$BUCKET \
--set secrets.s3accesskeyid=$ACCESS_KEY \
--set secrets.s3accesskey=$SECRET_KEY
解除安裝 Chart¶
要解除安裝 test-vllm 部署
該命令會移除與 Chart 相關的所有 Kubernetes 元件,**包括持久卷**,並刪除該釋出。
架構¶
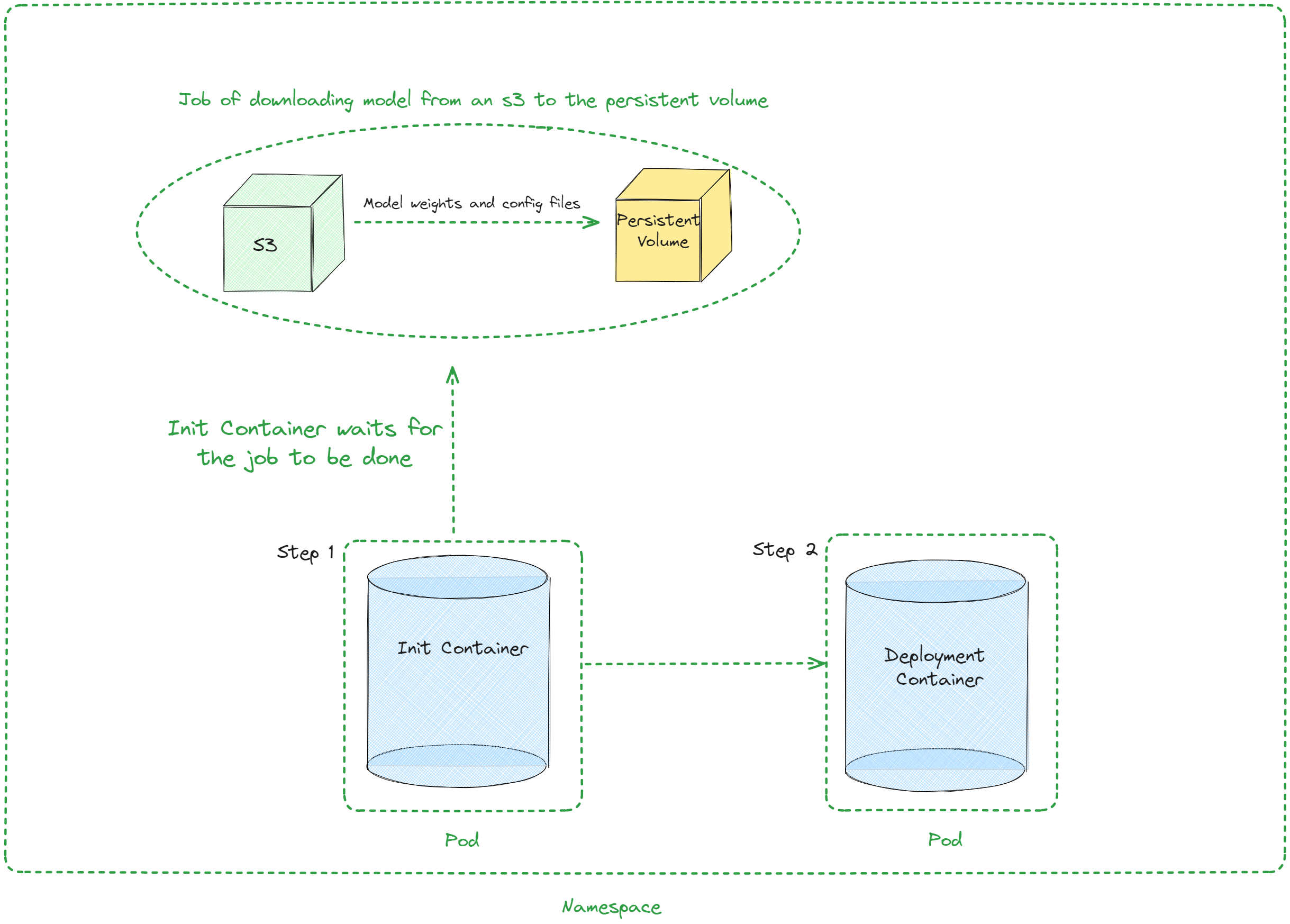
引數值¶
下表描述了 values.yaml 中 Chart 的可配置引數
| 鍵 | 型別 | 預設值 | 描述 |
|---|---|---|---|
| autoscaling | 物件 | {"enabled":false,"maxReplicas":100,"minReplicas":1,"targetCPUUtilizationPercentage":80} | 自動擴縮配置 |
| autoscaling.enabled | 布林值 | false | 啟用自動擴縮 |
| autoscaling.maxReplicas | 整型 | 100 | 最大副本數 |
| autoscaling.minReplicas | 整型 | 1 | 最小副本數 |
| autoscaling.targetCPUUtilizationPercentage | 整型 | 80 | 自動擴縮的目標 CPU 利用率 |
| configs | 物件 | {} | Configmap |
| containerPort | 整型 | 8000 | 容器埠 |
| customObjects | 列表 | [] | 自定義物件配置 |
| deploymentStrategy | 物件 | {} | 部署策略配置 |
| externalConfigs | 列表 | [] | 外部配置 |
| extraContainers | 列表 | [] | 額外容器配置 |
| extraInit | 物件 | {"pvcStorage":"1Gi","s3modelpath":"relative_s3_model_path/opt-125m", "awsEc2MetadataDisabled": true} | 初始化容器的額外配置 |
| extraInit.pvcStorage | 字串 | "1Gi" | S3 儲存桶的儲存大小 |
| extraInit.s3modelpath | 字串 | "relative_s3_model_path/opt-125m" | 託管模型權重和配置檔案的 S3 儲存桶上的模型路徑 |
| extraInit.awsEc2MetadataDisabled | 布林值 | true | 停用 Amazon EC2 例項元資料服務的使用 |
| extraPorts | 列表 | [] | 額外埠配置 |
| gpuModels | 列表 | ["TYPE_GPU_USED"] | 使用的 GPU 型別 |
| image | 物件 | {"command":["vllm","serve","/data/","--served-model-name","opt-125m","--host","0.0.0.0","--port","8000"],"repository":"vllm/vllm-openai","tag":"latest"} | 映象配置 |
| image.command | 列表 | ["vllm","serve","/data/","--served-model-name","opt-125m","--host","0.0.0.0","--port","8000"] | 容器啟動命令 |
| image.repository | 字串 | "vllm/vllm-openai" | 映象倉庫 |
| image.tag | 字串 | "latest" | 映象標籤 |
| livenessProbe | 物件 | {"failureThreshold":3,"httpGet":{"path":"/health","port":8000},"initialDelaySeconds":15,"periodSeconds":10} | 存活探針配置 |
| livenessProbe.failureThreshold | 整型 | 3 | 探針連續失敗的次數,在此之後 Kubernetes 會認為整體檢查失敗:容器不再存活 |
| livenessProbe.httpGet | 物件 | {"path":"/health","port":8000} | 伺服器上 kubelet http 請求的配置 |
| livenessProbe.httpGet.path | 字串 | "/health" | HTTP 伺服器上的訪問路徑 |
| livenessProbe.httpGet.port | 整型 | 8000 | 要訪問的容器埠的名稱或編號,伺服器在該埠上監聽 |
| livenessProbe.initialDelaySeconds | 整型 | 15 | 容器啟動後到存活探針開始執行前的秒數 |
| livenessProbe.periodSeconds | 整型 | 10 | 執行存活探針的頻率(秒) |
| maxUnavailablePodDisruptionBudget | 字串 | "" | 干擾預算配置 |
| readinessProbe | 物件 | {"failureThreshold":3,"httpGet":{"path":"/health","port":8000},"initialDelaySeconds":5,"periodSeconds":5} | 就緒探針配置 |
| readinessProbe.failureThreshold | 整型 | 3 | 探針連續失敗的次數,在此之後 Kubernetes 會認為整體檢查失敗:容器未就緒 |
| readinessProbe.httpGet | 物件 | {"path":"/health","port":8000} | 伺服器上 kubelet http 請求的配置 |
| readinessProbe.httpGet.path | 字串 | "/health" | HTTP 伺服器上的訪問路徑 |
| readinessProbe.httpGet.port | 整型 | 8000 | 要訪問的容器埠的名稱或編號,伺服器在該埠上監聽 |
| readinessProbe.initialDelaySeconds | 整型 | 5 | 容器啟動後到就緒探針開始執行前的秒數 |
| readinessProbe.periodSeconds | 整型 | 5 | 執行就緒探針的頻率(秒) |
| replicaCount | 整型 | 1 | 副本數 |
| resources | 物件 | {"limits":{"cpu":4,"memory":"16Gi","nvidia.com/gpu":1},"requests":{"cpu":4,"memory":"16Gi","nvidia.com/gpu":1}} | 資源配置 |
| resources.limits."nvidia.com/gpu" | 整型 | 1 | 使用的 GPU 數量 |
| resources.limits.cpu | 整型 | 4 | CPU 數量 |
| resources.limits.memory | 字串 | "16Gi" | CPU 記憶體配置 |
| resources.requests."nvidia.com/gpu" | 整型 | 1 | 使用的 GPU 數量 |
| resources.requests.cpu | 整型 | 4 | CPU 數量 |
| resources.requests.memory | 字串 | "16Gi" | CPU 記憶體配置 |
| secrets | 物件 | {} | 金鑰配置 |
| serviceName | 字串 | "" | 服務名稱 |
| servicePort | 整型 | 80 | 服務埠 |
| labels.environment | 字串 | test | 環境名稱 |