Dify¶
Dify 是一個開源的大模型應用開發平臺。它直觀的介面結合了智慧體AI工作流、RAG管線、智慧體能力、模型管理、可觀測性功能等,讓您能夠快速從原型部署到生產環境。
它支援vLLM作為模型提供商,以高效地服務大型語言模型。
本指南將引導您使用vLLM後端部署Dify。
先決條件¶
- 設定 vLLM 環境
- 安裝 Docker 和 Docker Compose
部署¶
- 啟動支援聊天完成模型的 vLLM 伺服器,例如
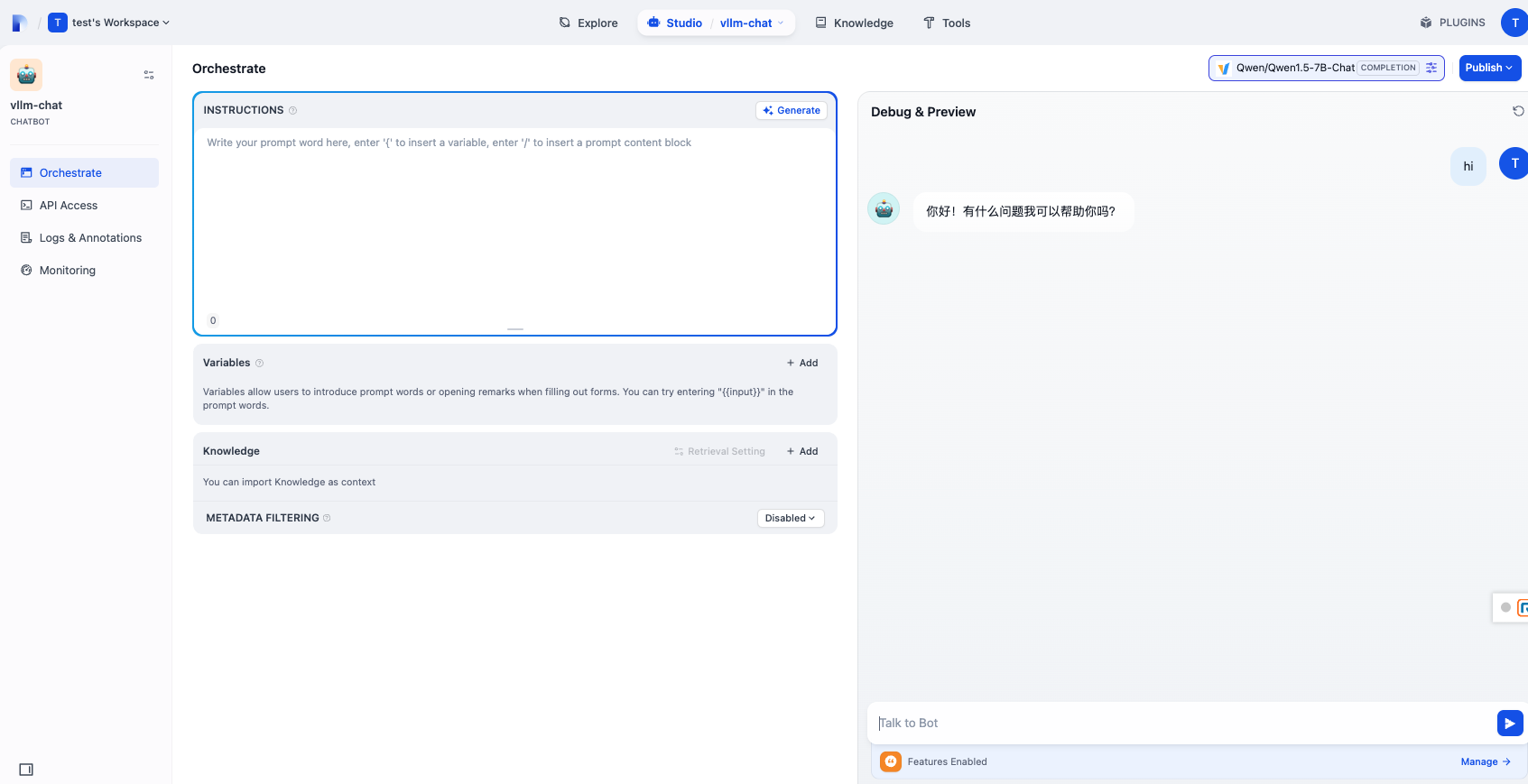
- 使用docker compose啟動Dify伺服器(詳情)
git clone https://github.com/langgenius/dify.git
cd dify
cd docker
cp .env.example .env
docker compose up -d
-
開啟瀏覽器訪問
https:///install,配置基本登入資訊並登入。 -
在右上角使用者選單(個人資料圖示下)中,進入“設定”,然後點選“模型提供商”,找到並安裝
vLLM提供商。 -
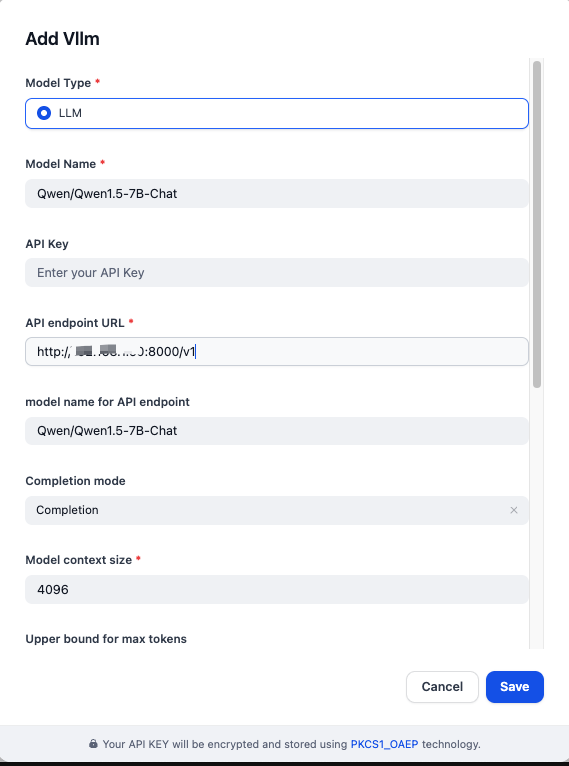
按如下填寫模型提供商詳情:
- 模型型別:
LLM - 模型名稱:
Qwen/Qwen1.5-7B-Chat - API 端點 URL:
http://{vllm_server_host}:{vllm_server_port}/v1 - API 端點模型名稱:
Qwen/Qwen1.5-7B-Chat - 補全模式:
Completion
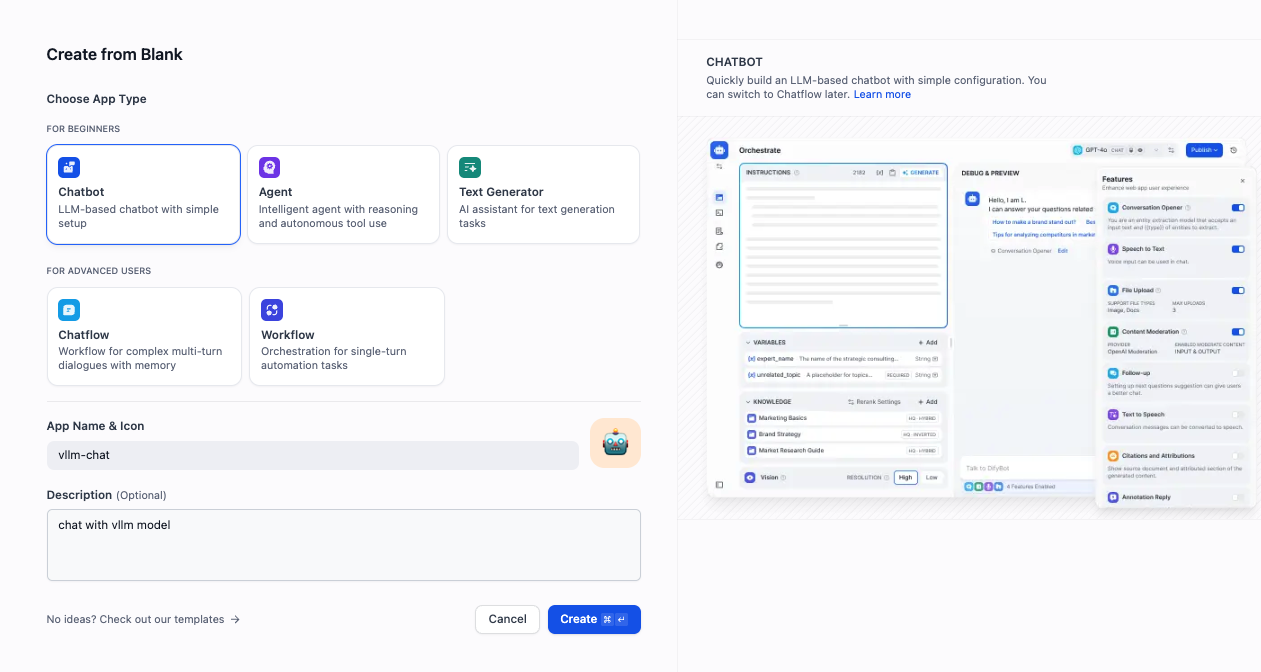
- 要建立一個測試聊天機器人,請前往
Studio → 聊天機器人 → 從空白建立,然後選擇“聊天機器人”作為型別。
- 點選您剛剛建立的聊天機器人以開啟聊天介面並開始與模型互動。