自動字首快取¶
字首快取 KV 快取塊是 LLM 推理中一種流行的最佳化方法,可避免冗餘的提示計算。其核心思想很簡單——我們快取已處理請求的 KV 快取塊,並在新請求帶有與之前請求相同的字首時重用這些塊。由於字首快取幾乎是免費的午餐,且不會改變模型輸出,因此它已被許多公共端點(例如 OpenAI、Anthropic 等)和大多數開源 LLM 推理框架(例如 SGLang)廣泛使用。
雖然有多種實現字首快取的方法,但 vLLM 選擇了一種基於雜湊的方法。具體來說,我們透過塊中的 token 和塊字首中的 token 對每個 KV 快取塊進行雜湊處理。
Block 1 Block 2 Block 3
[A gentle breeze stirred] [the leaves as children] [laughed in the distance]
Block 1: |<--- block tokens ---->|
Block 2: |<------- prefix ------>| |<--- block tokens --->|
Block 3: |<------------------ prefix -------------------->| |<--- block tokens ---->|
在上面的示例中,第一個塊中的 KV 快取可以透過 token“A gentle breeze stirred”唯一標識。第三個塊可以透過塊中的 token“laughed in the distance”以及字首 token“A gentle breeze stirred the leaves as children”唯一標識。因此,我們可以構建 hash(tuple[components]) 的塊雜湊,其中 components 是
- 父雜湊值:父雜湊塊的雜湊值。
- 塊 token:此塊中 token 的元組。包含精確 token 的原因是為了減少潛在的雜湊值衝突。
- 額外雜湊:使此塊獨一無二所需的其他值,例如 LoRA ID、多模態輸入雜湊(參見下面的示例)以及用於在多租戶環境中隔離快取的快取鹽值。
注意 1: 我們只快取完整的塊。
注意 2: 上述雜湊鍵結構並非 100% 無衝突。理論上,不同的字首 token 仍然可能具有相同的雜湊值。為了避免在多租戶設定中出現任何雜湊衝突,我們建議使用 SHA256 作為雜湊函式,而不是預設的內建雜湊。SHA256 從 vLLM v0.8.3 開始支援,並且必須透過命令列引數啟用。它會對效能產生約每 token 100-200 納秒的影響(對於 5 萬 token 的上下文,約 6 毫秒)。
多模態輸入的雜湊示例
在此示例中,我們將說明字首快取如何與多模態輸入(例如影像)一起工作。假設我們有一個包含以下訊息的請求
messages = [
{"role": "user",
"content": [
{"type": "text",
"text": "What's in this image?"
},
{"type": "image_url",
"image_url": {"url": image_url},
},
]},
]
它將變為以下提示
Prompt:
<s>[INST]What's in this image?\n[IMG][/INST]
Tokenized prompt:
[1, 3, 7493, 1681, 1294, 1593, 3937, 9551, 10, 4]
Prompt with placeholders (<P>):
[1, 3, 7493, 1681, 1294, 1593, 3937, 9551, <P>, <P>, ..., <P>, 4]
正如我們所看到的,在分詞之後,[IMG] 將被一系列佔位符 token 替換,而這些佔位符在預填充期間將被影像嵌入替換。字首快取支援這種情況的挑戰在於,我們需要區分影像和佔位符。為了解決這個問題,我們對前端影像處理器生成的影像雜湊進行編碼。例如,上述提示中塊的雜湊將是(假設塊大小為 16,我們有 41 個佔位符 token)
Block 0
Parent hash: None
Token IDs: 1, 3, 7493, 1681, 1294, 1593, 3937, 9551, <p>, ..., <p>
Extra hash: <image hash>
Block 1
Parent hash: Block 0 hash
Token IDs: <p>, ..., <p>
Extra hash: <image hash>
Block 2
Parent hash: Block 1 hash
Token IDs: <p>, ..., <p>
Extra hash: <image hash>
Block 3
Parent hash: Block 2 hash
Token IDs: <p>, ..., <p>, 4
Extra hash: <image hash>
在本文件的其餘部分,我們首先介紹 vLLM v1 中用於字首快取的資料結構,然後是主要 KV 快取運算子(例如,分配、追加、釋放、驅逐)的字首快取工作流程。最後,我們透過一個示例來演示端到端的字首快取工作流程。
快取隔離以提高安全性 為了提高共享環境中的隱私性,vLLM 支援透過可選的每個請求加鹽來隔離字首快取重用。透過在請求中包含一個 cache_salt,此值將被注入到第一個塊的雜湊中,從而確保只有具有相同鹽值的請求才能重用快取的 KV 塊。這可以防止攻擊者透過觀察延遲差異來推斷快取內容的基於時間的攻擊。這在不影響效能的情況下提供了保護。
{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Here is a document with details about the world series: ..."},
{"role": "user", "content": "Who won the world series in 2020?"}
],
"cache_salt": "your-cache-salt"
}
透過此設定,快取共享僅限於明確同意使用公共鹽的使用者或請求,從而實現在信任組內的快取重用,同時隔離其他組。
注意: 引擎 V0 不支援快取隔離。
資料結構¶
vLLM v1 中的字首快取是在 KV 快取管理器中實現的。其基本構建塊是“塊”資料類(簡化版)
class KVCacheBlock:
# The block ID (immutable)
block_id: int
# The block hash (will be assigned when the block is full,
# and will be reset when the block is evicted).
block_hash: BlockHash
# The number of requests using this block now.
ref_cnt: int
# The pointers to form a doubly linked list for the free queue.
prev_free_block: Optional["KVCacheBlock"] = None
next_free_block: Optional["KVCacheBlock"] = None
有兩點設計需要強調
- 我們在初始化 KV 快取管理器時分配所有 KVCacheBlock 作為塊池。這避免了 Python 物件建立的開銷,並且可以輕鬆地持續跟蹤所有塊。
- 我們直接在 KVCacheBlock 中引入雙向連結串列指標,以便可以直接構建空閒佇列。這給我們帶來了兩個好處
- 我們可以實現將中間元素移動到尾部的 O(1) 複雜度。
- 我們可以避免引入另一個 Python 佇列(例如
deque),因為它對元素有封裝。
因此,當 KV 快取管理器初始化時,我們將擁有以下元件

- 塊池:KVCacheBlock 的列表。
- 空閒塊佇列:僅儲存頭塊和尾塊的指標以進行操作。
- 快取塊:從雜湊鍵到塊 ID 的對映。
- 請求塊:從請求 ID 到已分配塊 ID 的對映。
操作¶
塊分配¶
新請求: 排程器排程帶有 KV 快取塊分配的新請求的工作流程
- 排程器呼叫
kv_cache_manager.get_computed_blocks()來獲取一系列已計算的塊。這是透過對請求中的提示 token 進行雜湊並查詢快取塊來完成的。 - 排程器呼叫
kv_cache_manager.allocate_slots()。它執行以下步驟- 計算所需新塊的數量,如果沒有足夠的塊可分配則返回。
- “觸碰”已計算的塊。它將已計算塊的引用計數增加一,如果該塊未被其他請求使用,則將其從空閒佇列中移除。這是為了避免這些已計算的塊被驅逐。有關說明,請參閱下一節中的示例。
- 透過彈出空閒佇列的頭部來分配新塊。如果頭部塊是快取塊,這也“驅逐”該塊,以便從現在開始其他請求不能再重用它。
- 如果一個已分配的塊已經滿了 token,我們立即將其新增到快取塊中,以便同一批次中的其他請求可以重用該塊。
正在執行的請求: 排程器排程帶有 KV 快取塊分配的正在執行請求的工作流程
- 排程器呼叫
kv_cache_manager.allocate_slots()。它執行以下步驟- 計算所需新塊的數量,如果沒有足夠的塊可分配則返回。
- 透過彈出空閒佇列的頭部來分配新塊。如果頭部塊是快取塊,這也“驅逐”該塊,以便從現在開始其他請求不能再重用它。
- 將 token ID 追加到現有塊以及新塊的槽位中。如果一個塊已滿,我們將其新增到快取塊以進行快取。
重複塊
假設塊大小為 4,您傳送一個請求(請求 1),其提示為 ABCDEF,解碼長度為 3
Prompt: [A, B, C, D, E, F]
Output: [G, H, I]
Time 0:
Tokens: [A, B, C, D, E, F, G]
Block Table: [0 (ABCD), 1 (EFG)]
Cache Blocks: 0
Time 1:
Tokens: [A, B, C, D, E, F, G, H]
Block Table: [0 (ABCD), 1 (EFGH)]
Cache Blocks: 0, 1
Time 2:
Tokens: [A, B, C, D, E, F, G, H, I]
Block Table: [0 (ABCD), 1 (EFGH), 2 (I)]
Cache Blocks: 0, 1
現在塊 0 和塊 1 被快取,我們再次使用貪婪取樣傳送相同的請求(請求 2),以便它將產生與請求 1 完全相同的輸出
Prompt: [A, B, C, D, E, F]
Output: [G, H, I]
Time 0:
Tokens: [A, B, C, D, E, F, G]
Block Table: [0 (ABCD), 3 (EFG)]
Cache Blocks: 0, 1
Time 1:
Tokens: [A, B, C, D, E, F, G, H]
Block Table: [0 (ABCD), 3 (EFGH)]
Cache Blocks: 0, 1, 3
可以看出,塊 3 是一個新的完整塊並被快取。然而,它與塊 1 是冗餘的,這意味著我們快取了相同的塊兩次。在 v0 中,當檢測到塊 3 重複時,我們釋放塊 3 並讓請求 2 使用塊 1,因此其塊表在時間 1 變為 [0, 1]。然而,vLLM v1 中的塊表是隻追加的,這意味著不允許將塊表從 [0, 3] 更改為 [0, 1]。因此,我們將為雜湊鍵 E-H 擁有重複的塊。這種重複將在請求被釋放時消除。
釋放¶
當請求完成後,如果沒有其他請求正在使用其塊(引用計數 = 0),我們將釋放其所有塊。在此示例中,我們釋放請求 1 以及與其關聯的塊 2、3、4、8。我們可以看到,被釋放的塊以反向順序新增到空閒佇列的尾部。這是因為請求的最後一個塊必須雜湊更多的 token,並且不太可能被其他請求重用。因此,它應該首先被驅逐。

驅逐 (LRU)¶
當空閒佇列的頭部塊(最近最少使用的塊)被快取時,我們必須驅逐該塊以防止其被其他請求使用。具體來說,驅逐涉及以下步驟
- 從空閒佇列的頭部彈出該塊。這是要被驅逐的 LRU 塊。
- 從快取塊中移除塊 ID。
- 移除塊雜湊。
示例¶
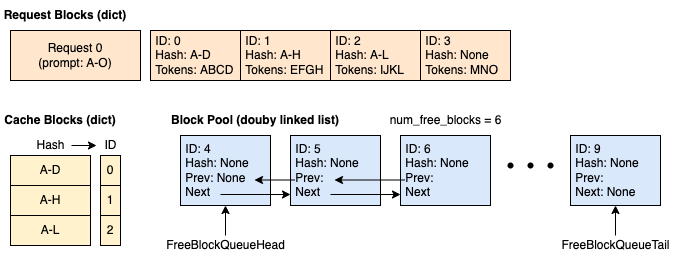
在此示例中,我們假設塊大小為 4(每個塊可以快取 4 個 token),並且 KV 快取管理器中總共有 10 個塊。
時間 1:快取為空,新請求進入。 我們分配 4 個塊。其中 3 個已滿並被快取。第四個塊部分已滿,包含 4 個 token 中的 3 個。
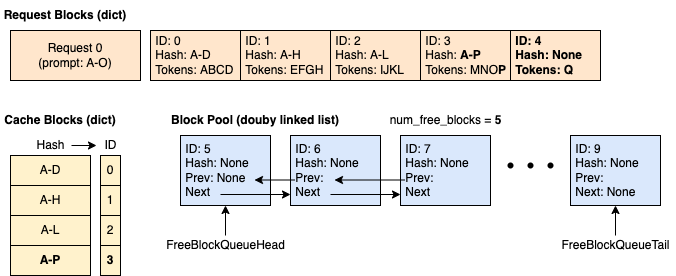
時間 3:請求 0 使塊 3 變滿並請求新塊以繼續解碼。 我們快取塊 3 並分配塊 4。
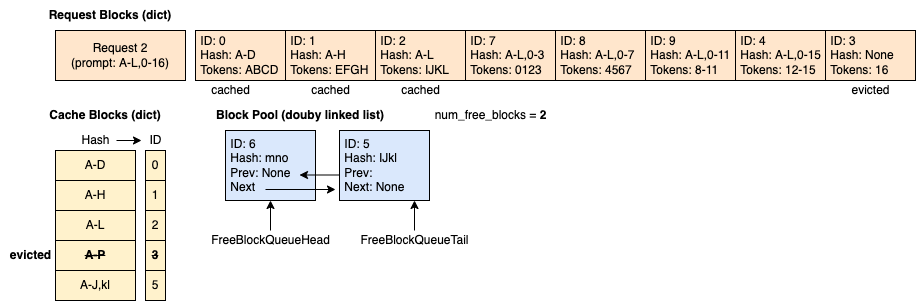
時間 4:請求 1 帶著 14 個提示 token 進入,其中前 10 個 token 與請求 0 相同。 我們可以看到只有前 2 個塊(8 個 token)命中了快取,因為第 3 個塊只匹配了 4 個 token 中的 2 個。
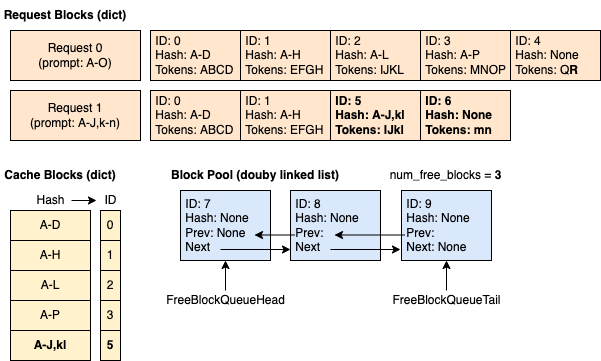
時間 5:請求 0 完成並釋放。 塊 2、3 和 4 以反向順序新增到空閒佇列(但塊 2 和 3 仍然被快取)。塊 0 和 1 未新增到空閒佇列,因為它們正被請求 1 使用。
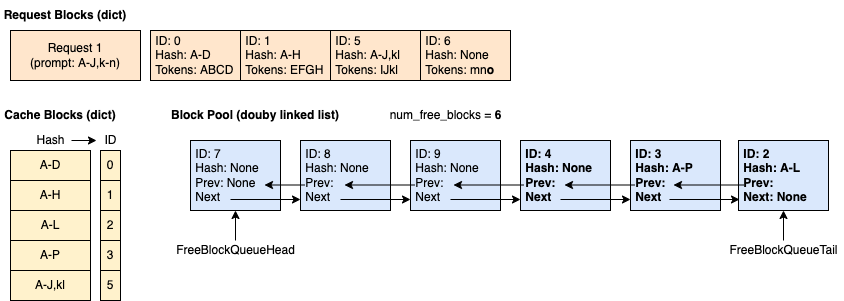
時間 6:請求 1 完成並釋放。

時間 7:請求 2 帶著 29 個提示 token 進入,其中前 12 個 token 與請求 0 相同。 請注意,儘管空閒佇列中的塊順序是 7 - 8 - 9 - 4 - 3 - 2 - 6 - 5 - 1 - 0,但快取命中的塊(即 0、1、2)在分配前被觸碰並從佇列中移除,因此空閒佇列變為 7 - 8 - 9 - 4 - 3 - 6 - 5。結果,分配的塊是 0(已快取)、1(已快取)、2(已快取)、7、8、9、4、3(已驅逐)。