指標¶
確保 v1 LLM 引擎暴露的指標是 v0 可用指標的超集。
目標¶
- 實現 v0 和 v1 之間的指標對等。
- 首要用例是透過 Prometheus 訪問這些指標,因為我們預期這將在生產環境中使用。
- 提供日誌支援(即,將指標列印到資訊日誌中),用於更即興的測試、除錯、開發和探索性用例。
背景¶
vLLM 中的指標可分為以下幾類:
- 伺服器級別指標:跟蹤 LLM 引擎狀態和效能的全域性指標。這些通常在 Prometheus 中作為 Gauges 或 Counters 暴露。
- 請求級別指標:跟蹤單個請求特徵(例如,大小和時間)的指標。這些通常在 Prometheus 中作為 Histograms 暴露,並且通常是 SRE 監控 vLLM 時會跟蹤的 SLO。
思維模型是伺服器級別指標有助於解釋請求級別指標的值。
v0 指標¶
在 v0 中,以下指標透過 Prometheus 相容的 /metrics 端點暴露,使用 vllm: 字首:
vllm:num_requests_running(Gauge)vllm:num_requests_swapped(Gauge)vllm:num_requests_waiting(Gauge)vllm:gpu_cache_usage_perc(Gauge)vllm:cpu_cache_usage_perc(Gauge)vllm:gpu_prefix_cache_hit_rate(Gauge)vllm:cpu_prefix_cache_hit_rate(Gauge)vllm:prompt_tokens_total(Counter)vllm:generation_tokens_total(Counter)vllm:request_success_total(Counter)vllm:request_prompt_tokens(Histogram)vllm:request_generation_tokens(Histogram)vllm:time_to_first_token_seconds(Histogram)vllm:time_per_output_token_seconds(Histogram)vllm:e2e_request_latency_seconds(Histogram)vllm:request_queue_time_seconds(Histogram)vllm:request_inference_time_seconds(Histogram)vllm:request_prefill_time_seconds(Histogram)vllm:request_decode_time_seconds(Histogram)vllm:request_max_num_generation_tokens(Histogram)vllm:num_preemptions_total(Counter)vllm:cache_config_info(Gauge)vllm:lora_requests_info(Gauge)vllm:tokens_total(Counter)vllm:iteration_tokens_total(Histogram)vllm:time_in_queue_requests(Histogram)vllm:model_forward_time_milliseconds(Histogram)vllm:model_execute_time_milliseconds(Histogram)vllm:request_params_n(Histogram)vllm:request_params_max_tokens(Histogram)vllm:spec_decode_draft_acceptance_rate(Gauge)vllm:spec_decode_efficiency(Gauge)vllm:spec_decode_num_accepted_tokens_total(Counter)vllm:spec_decode_num_draft_tokens_total(Counter)vllm:spec_decode_num_emitted_tokens_total(Counter)
這些在推理和服務 -> 生產指標下有文件記錄。
Grafana 儀表盤¶
vLLM 還提供了一個參考示例,說明如何使用 Prometheus 收集和儲存這些指標,並使用 Grafana 儀表盤進行視覺化。
Grafana 儀表盤中暴露的指標子集表明了哪些指標尤其重要:
vllm:e2e_request_latency_seconds_bucket- 端到端請求延遲,以秒為單位。vllm:prompt_tokens_total- 提示詞令牌數。vllm:generation_tokens_total- 生成令牌數。vllm:time_per_output_token_seconds- 令牌間延遲(每輸出令牌時間,TPOT),以秒為單位。vllm:time_to_first_token_seconds- 首令牌時間(TTFT)延遲,以秒為單位。vllm:num_requests_running(以及_swapped和_waiting) - 處於 RUNNING、WAITING 和 SWAPPED 狀態的請求數。vllm:gpu_cache_usage_perc- vLLM 使用的快取塊百分比。vllm:request_prompt_tokens- 請求提示長度。vllm:request_generation_tokens- 請求生成長度。vllm:request_success_total- 完成的請求數,按完成原因分類:生成了 EOS 令牌或達到最大序列長度。vllm:request_queue_time_seconds- 佇列時間。vllm:request_prefill_time_seconds- 請求預填充時間。vllm:request_decode_time_seconds- 請求解碼時間。vllm:request_max_num_generation_tokens- 序列組中的最大生成令牌數。
請參閱 新增此儀表盤的 PR,瞭解關於此處選擇的有趣且有用的背景資訊。
Prometheus 客戶端庫¶
Prometheus 支援最初是 使用 aioprometheus 庫新增的,但很快就切換到了 prometheus_client。理由在兩個連結的 PR 中都有討論。
切換到 aioprometheus 後,我們失去了用於跟蹤 HTTP 指標的 MetricsMiddleware,但這已透過 prometheus_fastapi_instrumentator 恢復。
$ curl http://0.0.0.0:8000/metrics 2>/dev/null | grep -P '^http_(?!.*(_bucket|_created|_sum)).*'
http_requests_total{handler="/v1/completions",method="POST",status="2xx"} 201.0
http_request_size_bytes_count{handler="/v1/completions"} 201.0
http_response_size_bytes_count{handler="/v1/completions"} 201.0
http_request_duration_highr_seconds_count 201.0
http_request_duration_seconds_count{handler="/v1/completions",method="POST"} 201.0
多程序模式¶
在 v0 中,指標在引擎核心程序中收集,我們使用多程序模式使其在 API 伺服器程序中可用。請參閱 拉取請求 #7279。
內建 Python/程序指標¶
以下指標是 prometheus_client 預設支援的,但在使用多程序模式時不暴露:
python_gc_objects_collected_totalpython_gc_objects_uncollectable_totalpython_gc_collections_totalpython_infoprocess_virtual_memory_bytesprocess_resident_memory_bytesprocess_start_time_secondsprocess_cpu_seconds_totalprocess_open_fdsprocess_max_fds
這之所以相關,是因為如果我們在 v1 中放棄多程序模式,我們將重新獲得這些指標。然而,如果它們不能聚合組成 vLLM 例項的所有程序的統計資訊,那麼這些指標的相關性就值得懷疑。
v0 PRs 和 Issues¶
作為背景,以下是一些新增 v0 指標的相關 PR:
另請注意 “更好的可觀測性”功能,其中例如 詳細路線圖已制定。
v1 設計¶
v1 PRs¶
作為背景,以下是與 v1 指標問題相關的 v1 PRs: 問題 #10582
- 拉取請求 #11962
- 拉取請求 #11973
- 拉取請求 #10907
- 拉取請求 #12416
- 拉取請求 #12478
- 拉取請求 #12516
- 拉取請求 #12530
- 拉取請求 #12561
- 拉取請求 #12579
- 拉取請求 #12592
- 拉取請求 #12644
指標收集¶
在 v1 中,我們希望將計算和開銷從引擎核心程序中移出,以最小化每次正向傳播之間的時間。
v1 EngineCore 設計的總體思路是:
- EngineCore 是內迴圈。效能在此處最關鍵。
- AsyncLLM 是外迴圈。這與 GPU 執行重疊(理想情況下),因此任何“開銷”都應該儘可能放在這裡。因此,AsyncLLM.output_handler_loop 是指標記賬的理想位置(如果可能的話)。
我們將透過在前端 API 伺服器中收集指標來實現這一點,並將這些指標基於我們從引擎核心程序返回到前端的 EngineCoreOutputs 中獲取的資訊。
間隔計算¶
我們的許多指標都是請求處理過程中各種事件之間的時間間隔。最佳實踐是使用基於“單調時間”(time.monotonic())而不是“掛鐘時間”(time.time())的時間戳來計算間隔,因為前者不受系統時鐘變化(例如,來自 NTP)的影響。
同樣重要的是要注意,單調時鐘在不同程序之間是不同的——每個程序都有自己的參考點。因此,比較來自不同程序的單調時間戳是沒有意義的。
因此,為了計算間隔,我們必須比較來自同一程序的兩個單調時間戳。
排程器統計¶
引擎核心程序將從排程器收集一些關鍵統計資訊——例如,在上次排程器通過後排程或等待的請求數量——並將這些統計資訊包含在 EngineCoreOutputs 中。
引擎核心事件¶
引擎核心還將記錄某些請求事件的時間戳,以便前端可以計算這些事件之間的時間間隔。
事件包括:
QUEUED- 請求被引擎核心接收並新增到排程器佇列時。SCHEDULED- 請求首次被排程執行時。PREEMPTED- 請求已被放回等待佇列,以便為其他請求完成騰出空間。它將在未來重新排程並重新啟動其預填充階段。NEW_TOKENS-EngineCoreOutput中包含的輸出生成時。由於這對於給定迭代中的所有請求都是通用的,因此我們在EngineCoreOutputs上使用單個時間戳來記錄此事件。
計算出的間隔是:
- 佇列間隔 - 在
QUEUED和最近的SCHEDULED之間。 - 預填充間隔 - 在最近的
SCHEDULED和隨後的第一個NEW_TOKENS之間。 - 解碼間隔 - 在第一個(在最近的
SCHEDULED之後)和最後一個NEW_TOKENS之間。 - 推理間隔 - 在最近的
SCHEDULED和最後一個NEW_TOKENS之間。 - 令牌間間隔 - 在連續的
NEW_TOKENS之間。
換句話說:
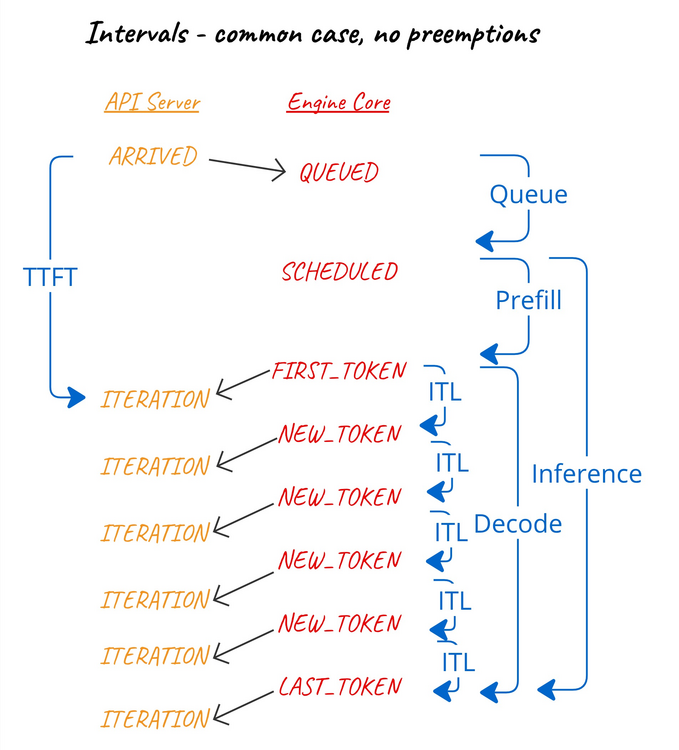
我們探討了讓前端使用前端可見事件的時間來計算這些間隔的可能性。然而,前端無法看到 QUEUED 和 SCHEDULED 事件的時間,而且,由於我們需要根據來自同一程序的單調時間戳計算間隔……我們需要引擎核心記錄所有這些事件的時間戳。
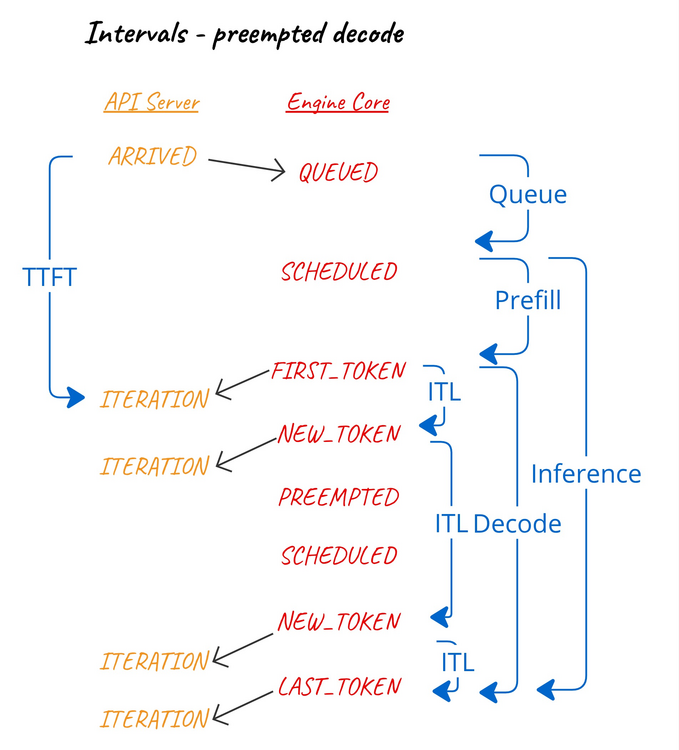
間隔計算與搶佔¶
當在解碼期間發生搶佔時,由於任何已生成的令牌都將被重用,我們將搶佔視為影響令牌間、解碼和推理間隔。
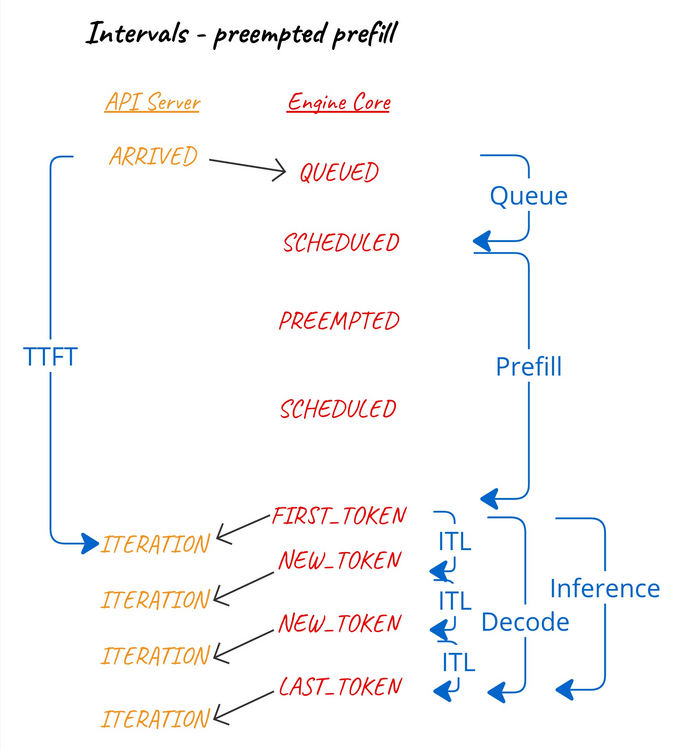
當在預填充期間發生搶佔時(假設此類事件可能發生),我們將搶佔視為影響首令牌時間和預填充間隔。
前端統計收集¶
當前端處理單個 EngineCoreOutputs——即單個引擎核心迭代的輸出——它會收集與該迭代相關的各種統計資訊:
- 本次迭代中生成的新令牌總數。
- 本次迭代中完成預填充的預填充所處理的提示令牌總數。
- 本次迭代中排程的任何請求的佇列間隔。
- 本次迭代中完成預填充的任何請求的預填充間隔。
- 本次迭代中包含的所有請求的令牌間間隔(每輸出令牌時間,TPOT)。
- 本次迭代中完成預填充的任何請求的首令牌時間(TTFT)。然而,我們計算此間隔是相對於請求首次被前端接收的時間(
arrival_time),以考慮輸入處理時間。
對於給定迭代中完成的任何請求,我們還記錄:
- 推理和解碼間隔 - 相對於排程和首令牌事件,如上所述。
- 端到端延遲 - 前端
arrival_time與前端接收到最終令牌之間的時間間隔。
指標釋出 - 日誌¶
LoggingStatLogger 指標釋出器每 5 秒輸出一個日誌 INFO 訊息,其中包含一些關鍵指標:
- 當前執行/等待請求的數量
- 當前 GPU 快取使用情況
- 過去 5 秒內每秒處理的提示令牌數量
- 過去 5 秒內每秒生成的新令牌數量
- 最近 1k kv-快取塊查詢的字首快取命中率
指標釋出 - Prometheus¶
PrometheusStatLogger 指標釋出器透過 /metrics HTTP 端點以 Prometheus 相容的格式提供指標。然後可以配置 Prometheus 例項來輪詢此端點(例如,每秒),並在其時間序列資料庫中記錄這些值。Prometheus 通常透過 Grafana 使用,允許這些指標隨時間繪製圖表。
Prometheus 支援以下指標型別:
- Counter(計數器):一個隨時間增加、永不減少的值,通常在 vLLM 例項重啟時重置為零。例如,例項生命週期內生成的令牌總數。
- Gauge(儀表):一個可升可降的值,例如當前排程執行的請求數量。
- Histogram(直方圖):度量樣本的計數,記錄在桶中。例如,TTFT <1ms、<5ms、<10ms、<20ms 等的請求數量。
Prometheus 指標也可以進行標記,允許根據匹配的標籤組合指標。在 vLLM 中,我們為每個指標新增一個 model_name 標籤,其中包含該例項服務的模型名稱。
示例輸出
$ curl http://0.0.0.0:8000/metrics
# HELP vllm:num_requests_running Number of requests in model execution batches.
# TYPE vllm:num_requests_running gauge
vllm:num_requests_running{model_name="meta-llama/Llama-3.1-8B-Instruct"} 8.0
...
# HELP vllm:generation_tokens_total Number of generation tokens processed.
# TYPE vllm:generation_tokens_total counter
vllm:generation_tokens_total{model_name="meta-llama/Llama-3.1-8B-Instruct"} 27453.0
...
# HELP vllm:request_success_total Count of successfully processed requests.
# TYPE vllm:request_success_total counter
vllm:request_success_total{finished_reason="stop",model_name="meta-llama/Llama-3.1-8B-Instruct"} 1.0
vllm:request_success_total{finished_reason="length",model_name="meta-llama/Llama-3.1-8B-Instruct"} 131.0
vllm:request_success_total{finished_reason="abort",model_name="meta-llama/Llama-3.1-8B-Instruct"} 0.0
...
# HELP vllm:time_to_first_token_seconds Histogram of time to first token in seconds.
# TYPE vllm:time_to_first_token_seconds histogram
vllm:time_to_first_token_seconds_bucket{le="0.001",model_name="meta-llama/Llama-3.1-8B-Instruct"} 0.0
vllm:time_to_first_token_seconds_bucket{le="0.005",model_name="meta-llama/Llama-3.1-8B-Instruct"} 0.0
vllm:time_to_first_token_seconds_bucket{le="0.01",model_name="meta-llama/Llama-3.1-8B-Instruct"} 0.0
vllm:time_to_first_token_seconds_bucket{le="0.02",model_name="meta-llama/Llama-3.1-8B-Instruct"} 13.0
vllm:time_to_first_token_seconds_bucket{le="0.04",model_name="meta-llama/Llama-3.1-8B-Instruct"} 97.0
vllm:time_to_first_token_seconds_bucket{le="0.06",model_name="meta-llama/Llama-3.1-8B-Instruct"} 123.0
vllm:time_to_first_token_seconds_bucket{le="0.08",model_name="meta-llama/Llama-3.1-8B-Instruct"} 138.0
vllm:time_to_first_token_seconds_bucket{le="0.1",model_name="meta-llama/Llama-3.1-8B-Instruct"} 140.0
vllm:time_to_first_token_seconds_count{model_name="meta-llama/Llama-3.1-8B-Instruct"} 140.0
注意
選擇最能為廣泛用例使用者提供幫助的直方圖桶並非易事,需要隨著時間的推移進行完善。
快取配置資訊¶
prometheus_client 支援資訊指標 (Info metrics),它等同於一個值永久設定為 1 的 Gauge,但透過標籤暴露有趣的鍵/值對資訊。這用於例項中不變的資訊——因此只需要在啟動時觀察——並允許在 Prometheus 中進行例項間比較。
我們將此概念用於 vllm:cache_config_info 指標:
# HELP vllm:cache_config_info Information of the LLMEngine CacheConfig
# TYPE vllm:cache_config_info gauge
vllm:cache_config_info{block_size="16",cache_dtype="auto",calculate_kv_scales="False",cpu_offload_gb="0",enable_prefix_caching="False",gpu_memory_utilization="0.9",...} 1.0
然而,prometheus_client 從未在多程序模式下支援資訊指標——原因 不明。我們簡單地使用一個設定為 1 的 Gauge 指標,並使用 multiprocess_mode="mostrecent" 代替。
LoRA 指標¶
vllm:lora_requests_info Gauge 有些類似,只是值是當前的掛鐘時間,並且每迭代更新一次。
使用的標籤名稱是:
running_lora_adapters: 每個介面卡上執行的使用該介面卡的請求計數,格式為逗號分隔的字串。waiting_lora_adapters: 類似,但計數的是等待排程的請求。max_lora- 靜態的“單個批次中最大 LoRA 數量”配置。
將多個介面卡的執行/等待計數編碼為逗號分隔的字串似乎相當誤導——我們可以使用標籤來區分每個介面卡的計數。這應該重新審視。
請注意,使用了 multiprocess_mode="livemostrecent"——使用最新的指標,但僅來自當前執行的程序。
這在 拉取請求 #9477 中新增,並且至少有一位已知使用者。如果我們重新審視這個設計並棄用舊指標,我們應該透過在 v0 中也進行更改並要求該專案遷移到新指標來減少長時間棄用期的需要。
字首快取指標¶
在 問題 #10582 中關於新增字首快取指標的討論提出了一些有趣的觀點,可能與我們未來如何處理指標相關。
每次查詢字首快取時,我們都會記錄查詢的令牌數量以及快取中存在的查詢令牌數量(即命中)。
然而,我們感興趣的指標是命中率——即每次查詢的命中次數。
在日誌記錄的情況下,我們期望使用者透過計算最近固定數量查詢的命中率來獲得最佳服務(目前間隔固定為最近 1k 次查詢)。
但在 Prometheus 的情況下,我們應該利用 Prometheus 的時間序列特性,允許使用者計算他們選擇的間隔內的命中率。例如,一個 PromQL 查詢來計算過去 5 分鐘的命中間隔:
為了實現這一點,我們應該將查詢和命中記錄為 Prometheus 中的計數器,而不是將命中率記錄為儀表。
已棄用指標¶
如何棄用¶
棄用指標不應輕率。使用者可能沒有注意到指標已被棄用,當指標突然(從他們的角度看)被移除時,即使有等效指標可用,也可能會給他們帶來不便。
例如,請看 vllm:avg_prompt_throughput_toks_per_s 是如何被 棄用(程式碼中有註釋),然後被 移除,然後被 使用者注意到。
通常來說:
- 我們應該謹慎棄用指標,尤其難以預測其對使用者的影響。
- 我們應該在
/metrics輸出的幫助字串中包含醒目的棄用通知。 - 我們應該在使用者文件和釋出說明中列出已棄用的指標。
- 我們應該考慮將棄用的指標隱藏在一個 CLI 引數後面,以便在刪除它們之前給管理員提供一段時間的“逃生艙口”。
請參閱棄用策略,瞭解專案範圍的棄用策略。
未實現 - vllm:tokens_total¶
由 拉取請求 #4464 新增,但顯然從未實現。這可以直接移除。
重複 - 佇列時間¶
vllm:time_in_queue_requests 直方圖指標由 拉取請求 #9659 新增,其計算方式是:
self.metrics.first_scheduled_time = now
self.metrics.time_in_queue = now - self.metrics.arrival_time
兩週後, 拉取請求 #4464 添加了 vllm:request_queue_time_seconds,導致我們有了:
if seq_group.is_finished():
if (seq_group.metrics.first_scheduled_time is not None and
seq_group.metrics.first_token_time is not None):
time_queue_requests.append(
seq_group.metrics.first_scheduled_time -
seq_group.metrics.arrival_time)
...
if seq_group.metrics.time_in_queue is not None:
time_in_queue_requests.append(
seq_group.metrics.time_in_queue)
這似乎是重複的,其中一個應該被移除。後者被 Grafana 儀表盤使用,因此我們應該棄用或移除 v0 中的前者。
字首快取命中率¶
見上文——我們現在暴露的是“查詢”和“命中”計數器,而不是“命中率”儀表。
KV 快取解除安裝¶
兩個 v0 指標與 v1 中不再相關的“交換”搶佔模式有關:
vllm:num_requests_swappedvllm:cpu_cache_usage_perc
在這種模式下,當請求被搶佔時(例如,為了在 KV 快取中為其他請求騰出空間),我們將 KV 快取塊交換到 CPU 記憶體。這也被稱為“KV 快取解除安裝”,並透過 --swap-space 和 --preemption-mode 進行配置。
在 v0 中, vLLM 長期支援束搜尋。SequenceGroup 封裝了 N 個序列共享相同提示 kv 塊的想法。這使得請求之間可以共享 KV 快取塊,並使用寫時複製進行分支。CPU 交換旨在用於這些類似束搜尋的情況。
後來,引入了字首快取的概念,它允許隱式共享 KV 快取塊。事實證明,這比 CPU 交換是更好的選擇,因為塊可以按需緩慢逐出,並且已逐出的提示部分可以重新計算。
SequenceGroup 已在 V1 中移除,儘管“並行取樣”(n>1)需要替換。在 V0 中, 束搜尋已移出核心。有很多複雜的程式碼用於一個非常不常見的功能。
在 V1 中,由於字首快取更好(零開銷)並且預設開啟,因此搶佔和重新計算策略應該更好地工作。
未來工作¶
並行取樣¶
一些 v0 指標僅與“並行取樣”相關。這是指請求中的 n 引數用於從同一提示請求多個完成。
作為在 拉取請求 #10980 中新增並行取樣支援的一部分,我們還應該新增這些指標。
vllm:request_params_n(Histogram)
觀察每個已完成請求的“n”引數值。
vllm:request_max_num_generation_tokens(Histogram)
觀察每個已完成序列組中所有序列的最大輸出長度。在沒有並行取樣的情況下,這等同於 vllm:request_generation_tokens。
推測解碼¶
一些 v0 指標特定於“推測解碼”。這是指我們使用更快、近似的方法或模型生成候選令牌,然後使用更大的模型驗證這些令牌。
vllm:spec_decode_draft_acceptance_rate(Gauge)vllm:spec_decode_efficiency(Gauge)vllm:spec_decode_num_accepted_tokens_total(Counter)vllm:spec_decode_num_draft_tokens_total(Counter)vllm:spec_decode_num_emitted_tokens_total(Counter)
有一個 PR 正在稽核中( 拉取請求 #12193),旨在向 v1 新增“提示查詢(ngram)”推測解碼。其他技術將隨之而來。我們應該在此背景下重新審視 v0 指標。
注意
我們可能應該將接受率暴露為單獨的接受計數器和草稿計數器,就像我們對字首快取命中率所做的那樣。效率可能也需要類似的處理。
自動擴縮和負載均衡¶
我們指標的一個常見用例是支援 vLLM 例項的自動化擴縮。
有關來自 Kubernetes 服務工作組的相關討論,請參閱:
這是一個不容忽視的話題。考慮一下 Rob 的評論:
我認為這個指標應該著重於嘗試估計最大併發量,這將導致平均請求長度 > 每秒查詢量……因為這才是真正會“飽和”伺服器的原因。
一個明確的目標是,我們應該暴露檢測此飽和點所需的指標,以便管理員可以根據這些指標實施自動擴縮規則。然而,為了做到這一點,我們需要清楚地瞭解管理員(和自動化監控系統)應該如何判斷例項何時接近飽和:
為了識別模型伺服器計算的飽和點(即在更高請求率下無法獲得更高吞吐量,但會開始產生額外延遲的拐點),我們如何才能有效地自動擴縮?
指標命名¶
我們命名指標的方法可能值得重新審視:
- 在指標名稱中使用冒號似乎與“冒號保留用於使用者自定義記錄規則”相悖。
- 我們的大多數指標都遵循以單位結尾的約定,但並非所有都如此。
-
我們的一些指標名稱以
_total結尾:如果指標名稱中帶有
_total字尾,它將被移除。當暴露計數器的時間序列時,將新增_total字尾。這是為了 OpenMetrics 和 Prometheus 文字格式之間的相容性,因為 OpenMetrics 要求使用_total字尾。
新增更多指標¶
新的指標構想層出不窮:
- 來自其他專案(如 TGI)的示例
- 源於特定用例的提議,如上文的 Kubernetes 自動擴縮主題
- 可能源於標準化工作的提議,如OpenTelemetry 生成式 AI 語義約定。
我們應該謹慎對待新增新指標。雖然指標通常相對容易新增,但:
- 它們可能難以移除——請參閱上文的棄用部分。
- 啟用時可能會對效能產生顯著影響。而且,除非可以預設在生產環境中啟用,否則指標的使用價值非常有限。
- 它們對專案的開發和維護產生影響。新增到 v0 的每個指標都使得這項 v1 工作更加耗時,而且並非所有指標都值得持續投入維護。
追蹤 - OpenTelemetry¶
指標提供了系統性能和健康狀況隨時間變化的聚合檢視。另一方面,追蹤則跟蹤單個請求在不同服務和元件之間的移動。兩者都屬於“可觀測性”這一更廣泛的範疇。
v0 支援 OpenTelemetry 追蹤:
- 由 拉取請求 #4687 新增
- 透過
--oltp-traces-endpoint和--collect-detailed-traces進行配置 - OpenTelemetry 部落格文章
- 面向使用者的文件
- 部落格文章
- IBM 產品文件
OpenTelemetry 設有一個生成式 AI 工作組。
鑑於指標本身是一個足夠大的話題,我們將把 v1 中追蹤的話題單獨處理。
OpenTelemetry 模型正向傳播與執行時間¶
在 v0 中,我們有以下兩個指標:
vllm:model_forward_time_milliseconds(直方圖) - 此請求在批處理中時,模型正向傳播所花費的時間。vllm:model_execute_time_milliseconds(直方圖) - 模型執行函式所花費的時間。這將包括模型正向傳播、跨工作器的塊/同步、CPU-GPU 同步時間和取樣時間。
這些指標僅在啟用 OpenTelemetry 追蹤且使用 --collect-detailed-traces=all/model/worker 時才啟用。此選項的文件指出:
收集指定模組的詳細追蹤。這可能涉及使用耗時或阻塞操作,因此可能對效能產生影響。
這些指標由 拉取請求 #7089 新增,並作為 OpenTelemetry 追蹤中的內容:
-> gen_ai.latency.time_in_scheduler: Double(0.017550230026245117)
-> gen_ai.latency.time_in_model_forward: Double(3.151565277099609)
-> gen_ai.latency.time_in_model_execute: Double(3.6468167304992676)
我們已經有了 inference_time 和 decode_time 指標,因此問題是更高解析度的時間是否有足夠常見的用例來證明其開銷是合理的。
由於我們將單獨處理 OpenTelemetry 支援的問題,因此我們將把這些特定指標納入該主題下。