架構概覽¶
本文件提供了 vLLM 架構的概覽。
入口點¶
vLLM 提供了多個與系統互動的入口點。下圖展示了它們之間的關係。
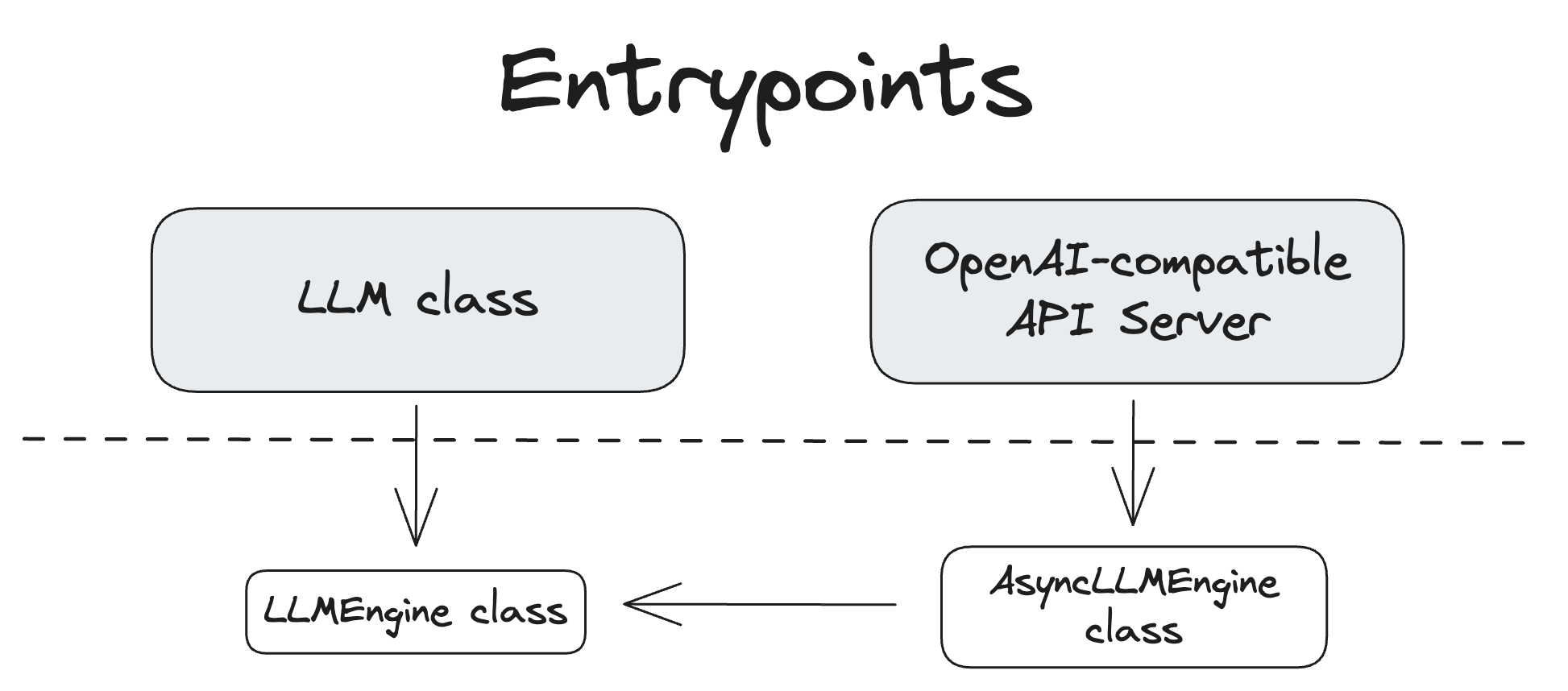
LLM 類¶
LLM 類提供了主要的 Python 介面,用於執行離線推理,即不使用單獨的模型推理伺服器即可與模型互動。
以下是 LLM 類用法的示例:
程式碼
from vllm import LLM, SamplingParams
# Define a list of input prompts
prompts = [
"Hello, my name is",
"The capital of France is",
"The largest ocean is",
]
# Define sampling parameters
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# Initialize the LLM engine with the OPT-125M model
llm = LLM(model="facebook/opt-125m")
# Generate outputs for the input prompts
outputs = llm.generate(prompts, sampling_params)
# Print the generated outputs
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
更多 API 詳情請參閱 API 文件的離線推理部分。
LLM 類的程式碼可以在 vllm/entrypoints/llm.py 中找到。
OpenAI 相容 API 伺服器¶
vLLM 的第二個主要介面是透過其 OpenAI 相容 API 伺服器。該伺服器可以使用 vllm serve 命令啟動。
vllm CLI 的程式碼可以在 vllm/entrypoints/cli/main.py 中找到。
有時您可能會看到 API 伺服器入口點被直接使用,而非透過 vllm CLI 命令。例如:
該程式碼可以在 vllm/entrypoints/openai/api_server.py 中找到。
更多關於 API 伺服器的詳情,請參閱 OpenAI 相容伺服器文件。
LLM 引擎¶
LLMEngine 和 AsyncLLMEngine 類是 vLLM 系統執行的核心,負責處理模型推理和非同步請求處理。
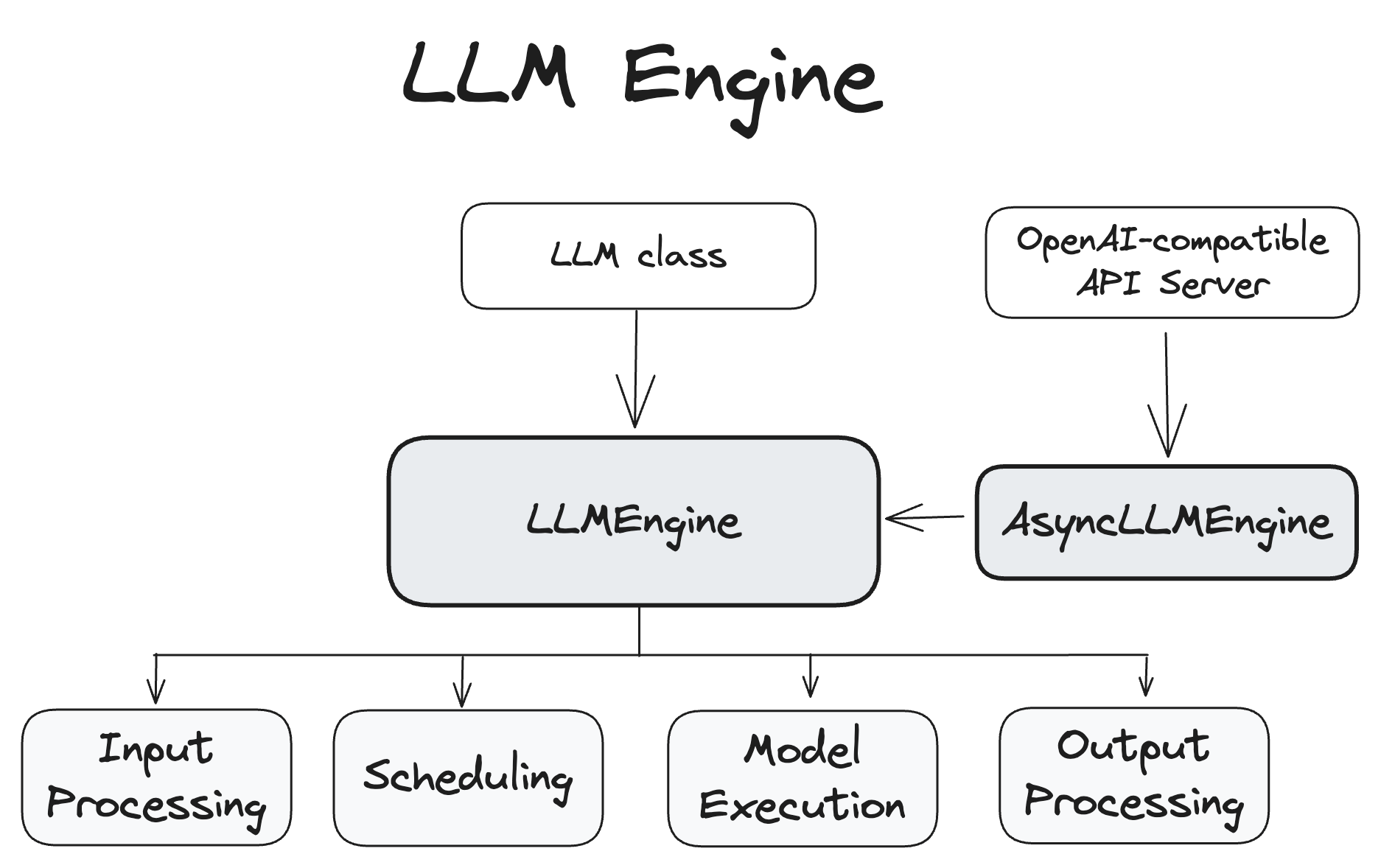
LLMEngine¶
LLMEngine 類是 vLLM 引擎的核心元件。它負責接收客戶端請求並從模型生成輸出。LLMEngine 包括輸入處理、模型執行(可能分佈在多個主機和/或 GPU 上)、排程和輸出處理。
- 輸入處理:使用指定的 Tokenizer 處理輸入文字的分詞。
- 排程:選擇在每個步驟中處理哪些請求。
- 模型執行:管理語言模型的執行,包括跨多個 GPU 的分散式執行。
- 輸出處理:處理模型生成的輸出,將語言模型中的 token ID 解碼為人類可讀的文字。
LLMEngine 的程式碼可以在 vllm/engine/llm_engine.py 中找到。
AsyncLLMEngine¶
AsyncLLMEngine 類是 LLMEngine 類的一個非同步封裝。它使用 asyncio 建立一個後臺迴圈,持續處理傳入請求。AsyncLLMEngine 專為線上服務設計,可以處理多個併發請求並將輸出流式傳輸到客戶端。
OpenAI 相容 API 伺服器使用 AsyncLLMEngine。還有一個演示 API 伺服器作為更簡單的示例,位於 vllm/entrypoints/api_server.py。
AsyncLLMEngine 的程式碼可以在 vllm/engine/async_llm_engine.py 中找到。
Worker¶
Worker 是執行模型推理的程序。vLLM 遵循使用一個程序控制一個加速裝置(如 GPU)的常見做法。例如,如果使用大小為 2 的張量並行和大小為 2 的流水線並行,則總共有 4 個 Worker。Worker 透過其 rank 和 local_rank 進行標識。rank 用於全域性編排,而 local_rank 主要用於分配加速裝置以及訪問檔案系統和共享記憶體等本地資源。
Model Runner¶
每個 Worker 都含有一個 Model Runner 物件,負責載入和執行模型。大部分模型執行邏輯都位於此處,例如準備輸入張量和捕獲 CUDA 圖。
模型¶
每個 Model Runner 物件都含有一個模型物件,即實際的 torch.nn.Module 例項。有關不同配置如何影響最終獲得的類,請參閱 huggingface_integration。
類層次結構¶
下圖展示了 vLLM 的類層次結構:
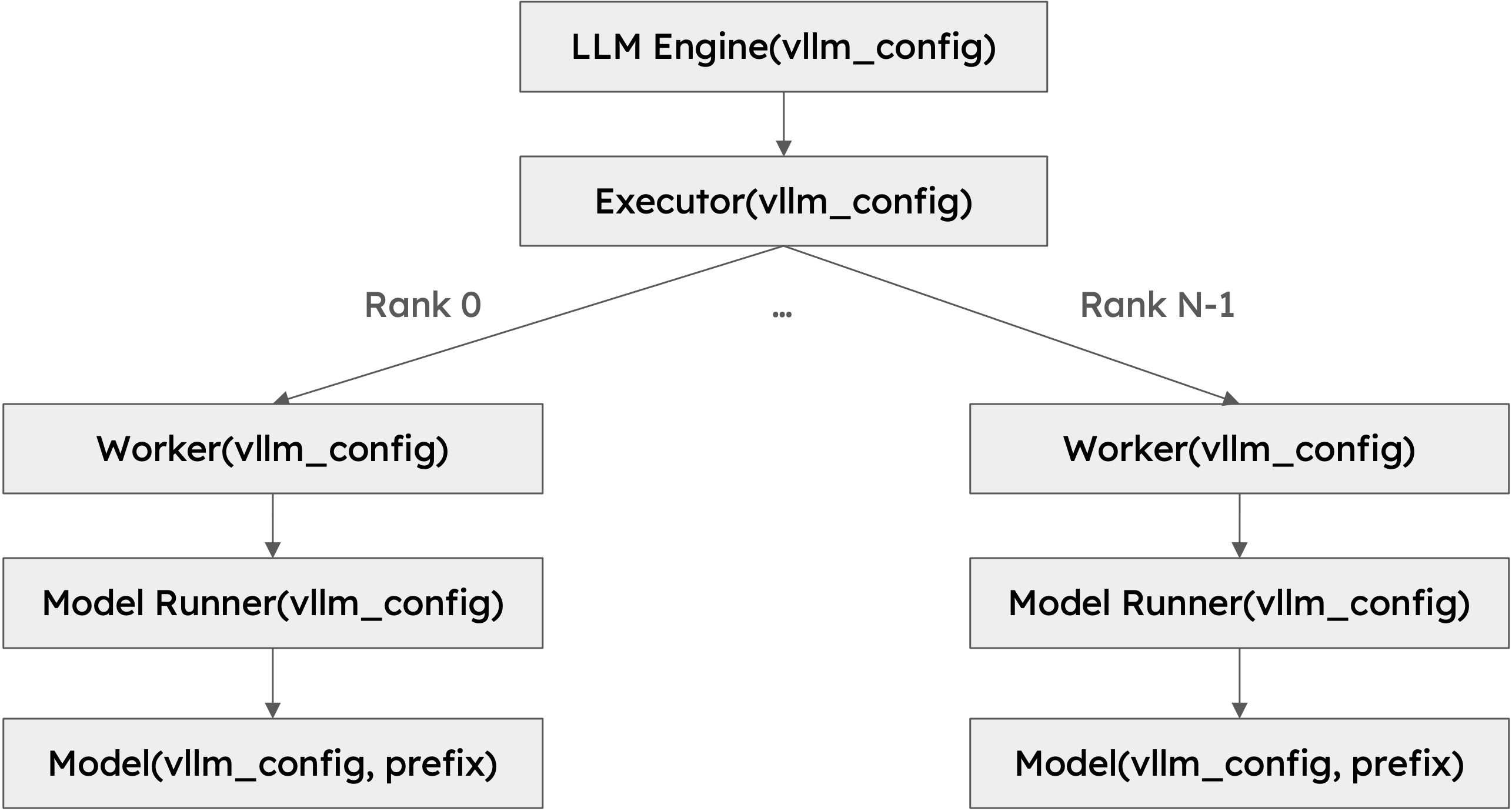
該類層次結構背後有幾個重要的設計選擇:
1. 可擴充套件性:層次結構中的所有類都接受一個包含所有必要資訊的配置物件。VllmConfig 類是主要且廣泛傳遞的配置物件。類層次結構相當深,每個類都需要讀取其感興趣的配置。透過將所有配置封裝在一個物件中,我們可以輕鬆地傳遞配置物件並訪問所需的配置。假設我們想新增一個只涉及 Model Runner 的新功能(考慮到 LLM 推理領域發展之快,這種情況很常見)。我們必須在 VllmConfig 類中新增一個新的配置選項。由於我們傳遞的是整個配置物件,所以我們只需要將配置選項新增到 VllmConfig 類中,Model Runner 就可以直接訪問它。我們無需更改引擎、Worker 或模型類的建構函式來傳遞新的配置選項。
2. 一致性:Model Runner 需要統一的介面來建立和初始化模型。vLLM 支援 50 多種流行的開源模型。每種模型都有自己的初始化邏輯。如果建構函式簽名因模型而異,Model Runner 將不知道如何相應地呼叫建構函式,這將導致複雜且容易出錯的檢查邏輯。透過統一模型類的建構函式,Model Runner 可以輕鬆地建立和初始化模型,而無需瞭解具體的模型型別。這對於組合模型也很有用。視覺-語言模型通常由視覺模型和語言模型組成。透過統一建構函式,我們可以輕鬆地建立視覺模型和語言模型,並將它們組合成一個視覺-語言模型。
注意
為支援此更改,所有 vLLM 模型的簽名已更新為:
為避免意外傳遞不正確的引數,建構函式現在僅接受關鍵字引數。這確保瞭如果傳遞舊配置,建構函式將引發錯誤。vLLM 開發者已經為 vLLM 中的所有模型進行了此更改。對於非樹內註冊模型,開發者需要更新其模型,例如透過新增 shim 程式碼來使舊的建構函式簽名適應新的簽名。
程式碼
class MyOldModel(nn.Module):
def __init__(
self,
config,
cache_config: Optional[CacheConfig] = None,
quant_config: Optional[QuantizationConfig] = None,
lora_config: Optional[LoRAConfig] = None,
prefix: str = "",
) -> None:
...
from vllm.config import VllmConfig
class MyNewModel(MyOldModel):
def __init__(self, *, vllm_config: VllmConfig, prefix: str = ""):
config = vllm_config.model_config.hf_config
cache_config = vllm_config.cache_config
quant_config = vllm_config.quant_config
lora_config = vllm_config.lora_config
super().__init__(config, cache_config, quant_config, lora_config, prefix)
if __version__ >= "0.6.4":
MyModel = MyNewModel
else:
MyModel = MyOldModel
透過這種方式,模型可以相容 vLLM 的舊版本和新版本。
3. 初始化時的分片和量化:某些功能需要更改模型權重。例如,張量並行需要對模型權重進行分片,而量化需要對模型權重進行量化。實現此功能有兩種可能的方法。一種是在模型初始化後更改模型權重,另一種是在模型初始化期間更改模型權重。vLLM 選擇了後者。第一種方法對於大型模型而言不可擴充套件。假設我們想在 16 個 H100 80GB GPU 上執行一個 405B 模型(大約 810GB 權重)。理想情況下,每個 GPU 應該只加載 50GB 權重。如果我們在模型初始化後更改模型權重,我們需要將完整的 810GB 權重載入到每個 GPU,然後進行分片,這將導致巨大的記憶體開銷。相反,如果我們在模型初始化期間對權重進行分片,則每一層只會建立其所需權重的一個分片,從而大大減少記憶體開銷。相同的思想也適用於量化。請注意,我們還在模型的建構函式中添加了一個額外的引數 prefix,以便模型可以根據該字首進行不同的初始化。這對於非均勻量化很有用,即模型的不同部分以不同方式進行量化。prefix 通常對於頂層模型是空字串,對於子模型則是諸如 "vision" 或 "language" 這樣的字串。通常,它與檢查點檔案中模組狀態字典的名稱匹配。
這種設計的一個缺點是,很難為 vLLM 中的單個元件編寫單元測試,因為每個元件都需要透過一個完整的配置物件進行初始化。我們透過提供一個預設初始化函式來解決這個問題,該函式建立一個所有欄位都設定為 None 的預設配置物件。如果我們要測試的元件只關心配置物件中的幾個欄位,我們可以建立一個預設配置物件並設定我們關心的欄位。透過這種方式,我們可以獨立地測試該元件。請注意,vLLM 中的許多測試都是端到端測試,用於測試整個系統,因此這不是一個大問題。
總而言之,完整的配置物件 VllmConfig 可以被視為一個引擎級別的全域性狀態,在所有 vLLM 類之間共享。